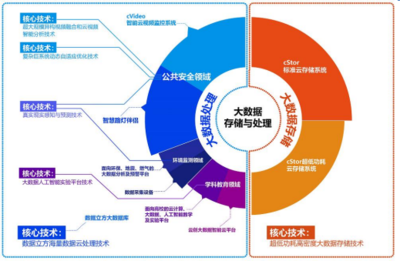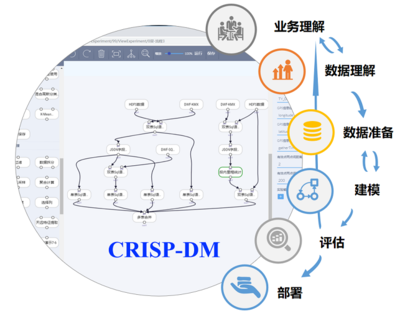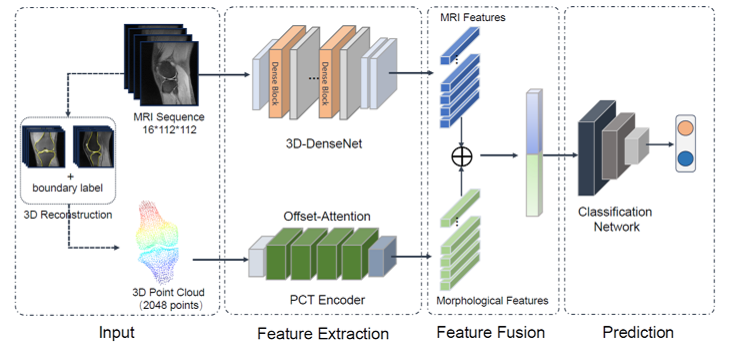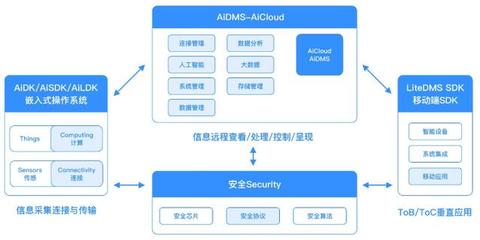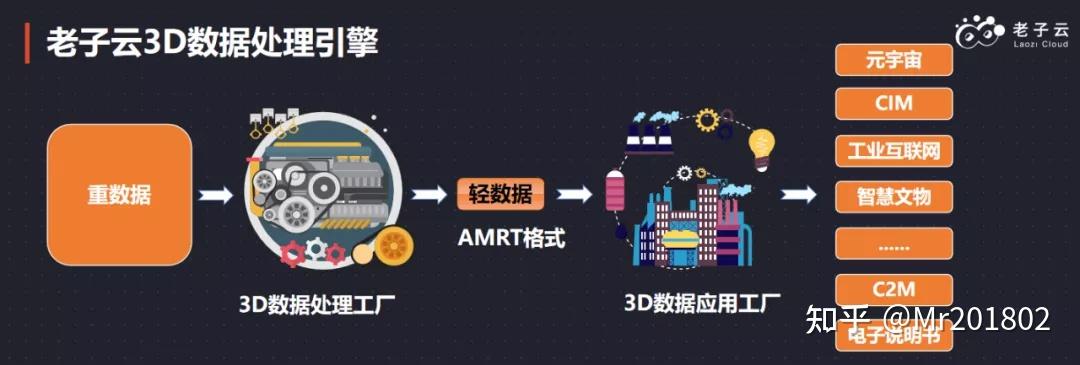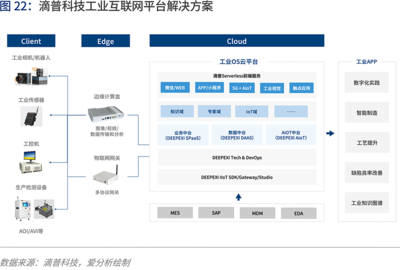
2020年,人工智能(AI)技术从概念验证迈向规模化应用的关键一年。在这一进程中,数据处理技术作为AI系统的基石,其成熟度与适用性直接决定了AI项目能否成功落地。本报告将深入剖析AI落地过程中数据处理环节面临的核心挑战,并探讨切实可行的应对策略。
一、核心挑战:从“实验室”到“生产线”的数据鸿沟
- 数据质量与标注瓶颈:现实世界的数据往往存在大量噪声、缺失值与不一致性。高质量的标注数据稀缺且成本高昂,特别是对于需要细粒度标注的计算机视觉、自然语言处理任务。弱监督、半监督学习虽为缓解标注压力提供了思路,但其在实际复杂场景中的泛化能力仍有待验证。
- 数据孤岛与隐私合规:企业数据常分散于不同部门与系统,形成“数据孤岛”,难以汇聚形成可用于训练的有效数据集。随着《个人信息保护法》等法规的出台,数据隐私与安全合规要求空前严格。如何在保障用户隐私与数据安全的前提下,合法合规地利用数据,成为必须跨越的障碍。联邦学习、差分隐私等技术提供了潜在解决方案,但其计算效率与模型性能的平衡仍需优化。
- 数据处理的实时性与工程化:许多AI应用场景,如实时风控、工业质检,要求数据处理与模型推理具备低延迟、高吞吐的特性。这要求数据处理管道(Data Pipeline)必须高度工程化、自动化,并能与模型训练、部署流程无缝集成。构建和维护这样一套健壮、高效的数据流水线,对团队的技术架构与工程能力提出了极高要求。
- 多模态与动态数据融合:AI应用正日益复杂,往往需要同时处理文本、图像、语音、时序数据等多种模态。如何有效地对齐、融合这些异构、动态变化的数据,从中提取统一、深层的语义信息,是提升模型认知能力的关键,也是当前技术的前沿难点。
二、应对策略:构建面向AI的数据基础设施与治理体系
面对上述挑战,企业需系统性地构建以AI为导向的数据能力,而非零散地解决单个问题。
- 实施以AI应用为目标的数据战略:企业应从顶层设计入手,将数据战略与AI业务目标紧密结合。规划统一的数据中台或数据湖,在合规框架下打破部门壁垒,实现数据的互联互通与统一治理,为AI提供高质量的“燃料”。
- 投资自动化与智能化的数据工程工具链:积极引入和开发自动化数据标注、数据清洗、特征工程工具,降低对人工的依赖,提升数据准备的效率与一致性。采用MLOps理念,将数据处理、模型训练、部署监控等环节流水线化,实现AI模型的持续集成与持续部署。
- 前瞻性布局隐私计算与安全技术:将隐私保护设计(Privacy by Design)理念融入数据处理全流程。积极探索联邦学习、安全多方计算、可信执行环境等隐私计算技术在业务场景中的试点应用,在数据“可用不可见”的前提下挖掘价值,筑牢合规防线。
- 培养跨领域的数据科学团队:成功的AI落地离不开既懂业务、又精通数据与算法的复合型人才。企业应着力培养或引进能够理解数据、处理数据并通过数据驱动决策的团队,弥合业务、数据科学与工程之间的 gap。
三、展望:数据处理技术的未来演进
数据处理技术将更加趋向自动化、智能化与实时化。AI for Data(利用AI技术来提升数据处理能力)将成为重要趋势,例如利用AI自动进行数据质量检测、关联发现与特征生成。云原生、边缘计算与数据处理的结合将更紧密,以支持无处不在的智能计算需求。
2020年及之后,数据处理已不再是AI的幕后辅助,而是决定其落地成败的主战场。只有系统性地克服数据层面的挑战,构建坚实、灵活、合规的数据基座,人工智能才能真正释放其 transformative(变革性)的潜力,驱动产业实现智能化升级。