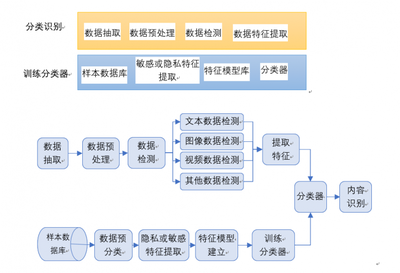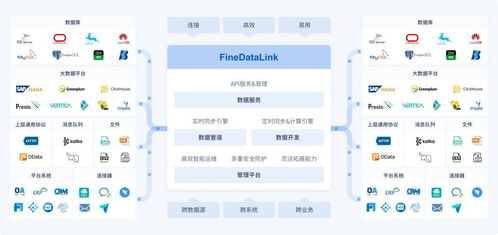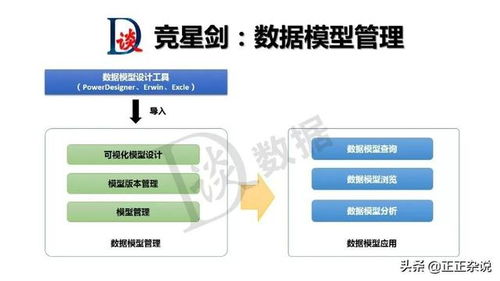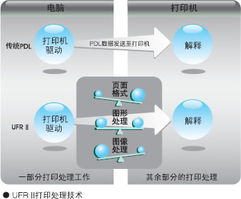
在当今数据驱动的时代,海量信息的涌现对数据处理技术提出了前所未有的挑战。传统的批处理模式往往存在延迟高、响应慢的瓶颈,难以满足业务对实时洞察与敏捷决策的迫切需求。在此背景下,交互式大数据处理与分析技术应运而生,它如同一场静默的革命,正在重塑我们探索与利用数据的范式。
交互式大数据处理的核心,在于其强调“低延迟”与“高并发”的用户体验。它允许分析师、业务人员甚至决策者通过直观的查询接口,直接对PB级甚至EB级的数据集发起即时查询,并在秒级甚至亚秒级内获得响应。这背后是一系列尖端数据处理技术的融合与创新。
内存计算技术是交互式处理的基石。通过将海量数据加载到分布式集群的高速内存(RAM)中进行分析,而非依赖传统的磁盘I/O,系统实现了数量级的性能飞跃。以Spark、Flink为代表的现代计算框架,其内存计算引擎能够将复杂查询的耗时从小时缩减至分钟乃至秒级。
预计算与智能索引技术扮演了“加速器”的角色。面对即席查询(Ad-hoc Query),系统通过列式存储(如Parquet、ORC)、数据立方体(Cube)或物化视图等方式,预先对数据进行聚合、排序与索引。当查询到来时,系统无需扫描全部原始数据,而是快速定位到预计算的结果或相关数据块,极大提升了查询效率。例如,Apache Kylin、Druid等OLAP引擎正是这方面的杰出代表。
分布式查询优化是保证系统高效运转的大脑。一个交互式查询可能被分解成数百上千个子任务,在庞大的集群中并行执行。查询优化器需要智能地制定执行计划,优化数据Shuffle(混洗)、资源分配与任务调度,以最小化网络传输与计算开销。向量化执行引擎等技术的引入,进一步压榨了CPU的处理潜能。
云原生与弹性伸缩架构为交互式处理提供了灵活的土壤。基于Kubernetes的容器化部署,使得计算与存储资源能够根据查询负载动态弹性伸缩。用户无需为峰值流量过度配置硬件,系统可以自动扩缩容,在保证性能的同时实现成本优化。云服务商提供的Serverless交互式查询服务(如AWS Athena、Google BigQuery)更是将这一便利性推向了极致。
交互式分析与可视化的紧密结合,构成了技术价值的闭环。强大的数据处理引擎需要与Tableau、Superset、Jupyter Notebook等前端分析工具无缝集成。用户通过拖拽、点选或自然语言即可发起查询,结果以丰富的图表、仪表盘实时呈现,使得数据探索变得直观而高效,真正实现了从“数据”到“洞见”的平滑过渡。
交互式大数据处理技术正朝着更智能、更融合的方向演进。机器学习与AI的集成,将使系统能够自动优化查询、预测热点数据并进行智能缓存。数据湖仓一体(Lakehouse)架构的兴起,则致力于打破事务处理(OLTP)、交互分析(OLAP)与数据科学之间的壁垒,在一个统一的平台上支持从实时交互到深度学习的全链路数据工作负载。
交互式大数据处理与分析技术已不再是锦上添花的工具,而是企业数字化转型的核心基础设施。它通过融合内存计算、预计算、分布式优化与云原生等一系列先进的数据处理技术,将数据处理的“速度”与“敏捷性”提升到了新的高度,赋能各行各业在数据的海洋中即时航行,精准捕捉每一朵价值的浪花。