引言
在数据分析领域,数据处理技术是核心基石。经过半年的系统学习与实践,我对数据处理相关的技术栈有了更深入的认知。本文汇总了关键知识点,并结合面试常见问题,为求职或技能提升提供参考。
一、数据处理技术栈概览
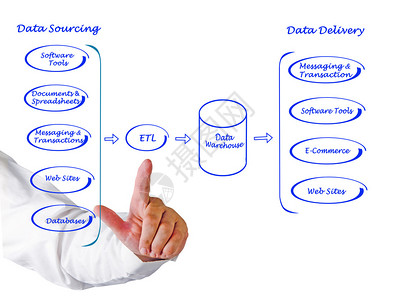
数据处理技术栈主要包括数据采集、清洗、转换、存储和集成等环节,覆盖从原始数据到可用数据的完整流程。
1. 数据采集与获取
- 技术工具:Python(Requests、Scrapy)、SQL、API接口、日志收集工具(如Fluentd)。
- 关键点:数据源的多样性(数据库、Web、文件),以及实时与批量采集的区分。
- 面试重点:解释如何设计数据采集流程,处理API限制或数据丢失问题。
2. 数据清洗与预处理
- 技术工具:Python(Pandas、NumPy)、SQL(CASE语句、WHERE过滤)、OpenRefine。
- 关键点:处理缺失值(删除、填充)、异常值检测(IQR方法)、数据标准化与规范化。
- 面试重点:举例说明如何处理脏数据,并讨论不同清洗方法的优缺点。
3. 数据转换与集成
- 技术工具:Python(Pandas转换函数)、SQL(JOIN操作)、ETL工具(如Apache NiFi、Talend)。
- 关键点:数据合并、聚合、重塑(如Pivot),以及处理数据不一致性问题。
- 面试重点:描述一个ETL项目经验,强调如何优化转换性能。
4. 数据存储与管理
- 技术工具:关系型数据库(MySQL、PostgreSQL)、NoSQL(MongoDB)、数据仓库(如BigQuery、Redshift)。
- 关键点:数据模型设计(星型模式、雪花模式)、分区与索引策略。
- 面试重点:比较不同存储方案的适用场景,解释数据仓库与数据库的区别。
5. 大数据处理框架
- 技术工具:Hadoop(HDFS、MapReduce)、Spark(PySpark、Spark SQL)、Flink。
- 关键点:分布式计算原理、内存优化、流处理与批处理集成。
- 面试重点:讨论Spark与Hadoop的优劣,并演示一个简单的数据处理代码示例。
二、面试关键点总结
在面试中,数据处理技术常通过项目经验、代码实现和理论问题来考察。以下为关键准备要点:
- 项目经验:准备1-2个完整的数据处理项目,突出数据清洗、转换和性能优化细节。
- 代码能力:熟练使用Python(Pandas、SQLAlchemy)或SQL编写数据处理脚本,并能解释时间复杂度。
- 理论问题:掌握数据质量评估方法、ETL流程设计,以及大数据框架的基础原理。
- 案例分析:练习处理模拟数据问题,如“如何从多个来源整合用户行为数据”。
结语
数据处理技术是数据分析师的必备技能,涉及工具广泛且实践性强。通过系统学习技术栈并聚焦面试关键点,可以有效提升竞争力。建议结合真实数据集练习,并关注行业趋势如云数据处理和自动化工具,以持续优化知识结构。