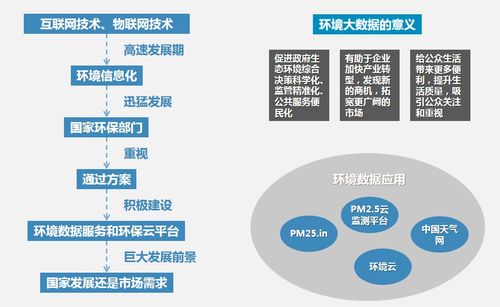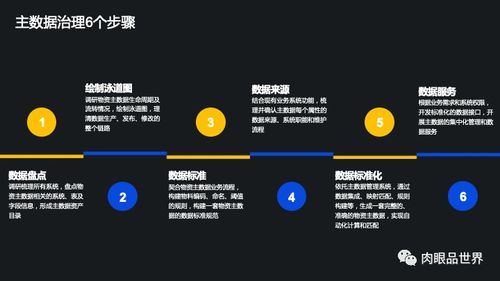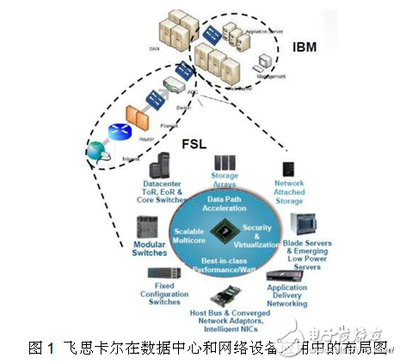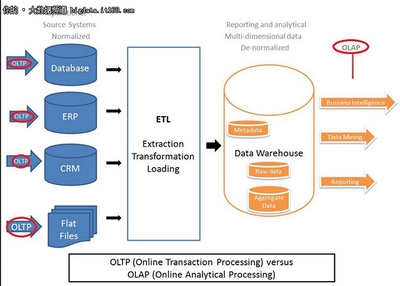
随着大数据技术的快速发展,Hadoop作为核心的数据处理框架,在企业中的应用越来越广泛。为了帮助大家更好地准备Hadoop相关面试,本文整理了25个常见的Hadoop面试问题及其详细解答。
1. 什么是Hadoop?它的核心组件有哪些?
答:Hadoop是一个开源的分布式计算框架,用于存储和处理大规模数据集。其核心组件包括HDFS(分布式文件系统)和MapReduce(分布式计算框架)。
2. HDFS的架构是怎样的?
答:HDFS采用主从架构,包含NameNode(主节点)和DataNode(从节点)。NameNode管理文件系统元数据,DataNode存储实际数据块。
3. 什么是MapReduce?
答:MapReduce是一种编程模型,用于并行处理大规模数据集。包含Map阶段(数据分割和处理)和Reduce阶段(数据汇总)。
4. Hadoop 1.0和Hadoop 2.0的主要区别是什么?
答:Hadoop 2.0引入了YARN(资源管理器),实现了计算资源和存储资源的分离,支持更多的计算框架。
5. 什么是YARN?
答:YARN是Hadoop 2.0中的资源管理框架,负责集群资源的管理和作业调度。
6. NameNode和DataNode的作用分别是什么?
答:NameNode管理文件系统命名空间和元数据;DataNode存储实际的数据块。
7. 什么是Secondary NameNode?
答:Secondary NameNode负责定期合并NameNode的编辑日志和镜像文件,防止编辑日志过大。
8. HDFS的数据复制机制是怎样的?
答:HDFS默认将数据块复制3份,分布在不同机架上,确保数据的高可用性。
9. MapReduce作业的执行流程?
答:包括输入分片、Map任务执行、Shuffle阶段、Reduce任务执行、输出写入等步骤。
10. 什么是Combiner?
答:Combiner是在Map端执行的本地Reduce操作,用于减少网络传输数据量。
11. 什么是Partitioner?
答:Partitioner决定Map输出的键值对发送到哪个Reduce任务。
12. Hadoop与关系型数据库的主要区别?
答:Hadoop适合批处理非结构化数据,支持线性扩展;关系数据库适合事务处理和结构化数据。
13. 什么是Hadoop生态系统?
答:包括HDFS、MapReduce、Hive、HBase、Pig、Spark等组件构成的完整大数据处理平台。
14. Hive是什么?
答:Hive是基于Hadoop的数据仓库工具,提供类SQL查询功能。
15. HBase的特点是什么?
答:HBase是分布式列式数据库,支持实时读写,适合随机访问。
16. 什么是Pig?
答:Pig是高级数据流语言和执行框架,用于简化MapReduce编程。
17. Hadoop集群的硬件配置建议?
答:建议使用多核CPU、大内存、多硬盘的服务器,网络带宽要充足。
18. Hadoop的容错机制如何实现?
答:通过数据副本、任务重试、心跳检测等机制保证系统可靠性。
19. 什么是数据本地化?
答:将计算任务调度到存储数据的节点上执行,减少网络传输。
20. Hadoop的瓶颈通常在哪里?
答:常见的瓶颈包括NameNode单点故障、小文件问题、网络带宽限制等。
21. 如何优化MapReduce作业?
答:合理设置Map和Reduce数量、使用Combiner、优化数据序列化等。
22. 什么是Hadoop的小文件问题?
答:大量小文件会占用过多NameNode内存,影响系统性能。
23. 如何解决小文件问题?
答:使用SequenceFile、Har文件或合并小文件。
24. Hadoop的安全机制有哪些?
答:包括Kerberos认证、访问控制列表、数据加密等。
25. Hadoop 3.0有哪些新特性?
答:包括Erasure Coding、多NameNode支持、GPU调度等特性。
这些问题的掌握程度直接关系到Hadoop面试的成功率,建议结合实际项目经验进行深入学习。掌握这些知识点不仅有助于面试,更能为实际的大数据项目开发打下坚实基础。